
The Year the Commodity Layer Ate the Stack
Why the “models commoditize, apps win” thesis broke — and where AI infrastructure value may move next.

The Tuesday Morning Chart
A SemiAnalysis report dropped on a Tuesday morning in late April 2026. Most people skimmed it for GPU shipment numbers. Buried about a third of the way down was a chart that, if you ran a venture fund in 2024, should have made you put down your coffee.

Anthropic’s annualized revenue, end of 2025: roughly nine billion dollars. Six months later, mid-2026: more than forty-four billion. Inference gross margin in that same window: thirty-eight percent, climbing past seventy. On SemiAnalysis’s view of enterprise AI spending, Anthropic had for the first time moved ahead of OpenAI on some measures. A single product inside the company — Claude Code — was doing two and a half billion in ARR, nine months after public launch, per SemiAnalysis figures reported by OfficeChai.
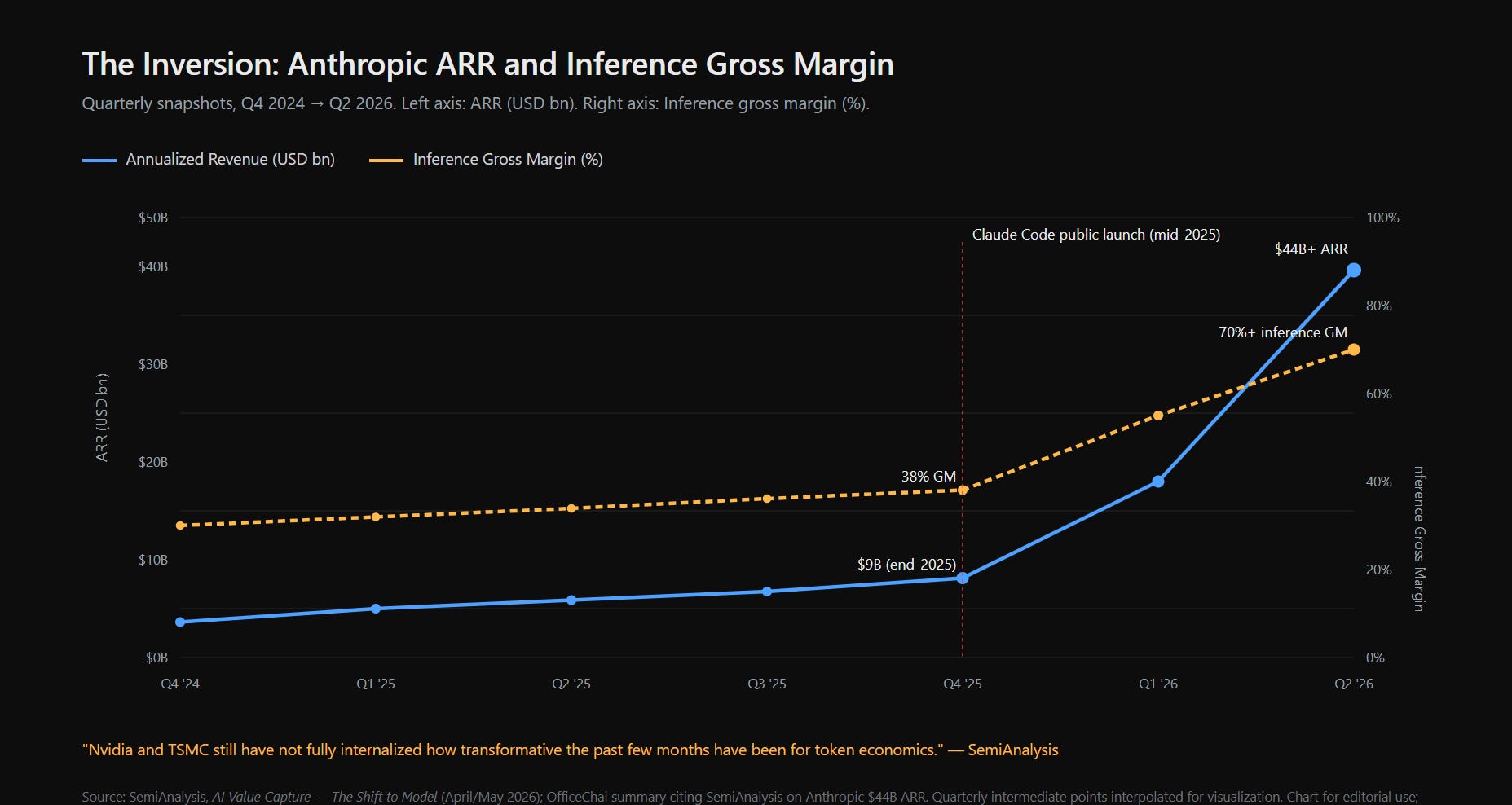
The inversion: Anthropic ARR and inference gross margin, Q4 2024 → Q2 2026. Source: SemiAnalysis; OfficeChai summary. Intermediate quarterly points are interpolated for visualization.
Note: Several company-level figures in this piece are reported estimates rather than audited financials. I use them directionally to analyze stack economics, not as certified financials.
This chart is not a victory lap. It is not a forecast. It is not proof that every model lab wins. It is evidence that the model layer can capture operating leverage under the right conditions: a high-willingness-to-pay workload, a real quality gap, and a serving stack where cost-to-serve falls faster than price-to-charge.
Those conditions existed in this window. Whether they persist is a separate question.
What the chart does challenge is the 2024 consensus — the one most LP letters, most Sequoia memos, most a16z theses aligned on. That consensus said this could not happen. Tokens commoditize. Models commoditize. Value flows up to applications. The model layer is the dumb pipe in the middle.
In this window, that consensus did not just bend. It looked inverted.
The Steelman of the View That Just Broke
Before dismantling the 2024 consensus, give it its best argument. Because honestly, the argument was reasonable.
Foundation-model intelligence got cheaper by roughly an order of magnitude every twelve to eighteen months. GPT-4-class capability that cost forty dollars per million tokens in early 2023 cost less than a dollar by late 2025. When an input collapses in price that fast, in any market, the input sellers cannot capture durable margin. They are toll-takers on a road that gets wider every quarter.
So the value, in 2024 thinking, had to flow up: to wrappers, vertical applications, agents, and companies that bundled cheapening intelligence with proprietary data, distribution, workflow, or brand.
And the pricing corollary followed naturally. If tokens are commodities, you cannot price on tokens. You price on outcomes. Per resolved ticket. Per booked meeting. Per closed dispute. Outcome pricing was — in every conference talk and most term sheets — the future.
This was not a fringe view. This was the consensus — and the next two years of capital deployment were underwritten by it.
That consensus was not stupid. It was incomplete.
It assumed the most important variable was the average cost of intelligence. It underweighted the distribution of difficulty: the fact that easy tasks commoditize faster than hard tasks, and that hard tasks are exactly where enterprise willingness to pay concentrates.
It also assumed the model layer would behave like a standard software input. But the model layer is not only software. It is training compute, data, alignment, evals, memory bandwidth, networking, serving systems, and power. In other words, it is not just an API. It is a constraint layer.
The Hidden Cost of Exceptions
In May 2025, Sebastian Siemiatkowski — the Klarna CEO who in 2024 had made his company the poster child of agentic customer service by replacing roughly seven hundred human agents — quietly told the press he was hiring humans back. Specifically for complex disputes, fraud cases, and hardship calls. The reason: quality on hard cases fell below the human baseline.
Klarna should not be read as proof that agentic customer service failed. The better lesson is narrower: exception handling is expensive, and exceptions do not disappear because a workflow is labeled “agentic.” Fraud cases, hardship calls, disputes — those are exactly the cases where a wrong answer is worse than no answer. For an outcome-priced vendor, they are also the cases where the contract pays nothing and the vendor eats the escalation cost.
LangChain’s State of Agent Engineering points to the same pattern across the enterprise cohort. Production adoption is real, but quality, eval coverage, and reliability remain major deployment bottlenecks. The more sophisticated the buyer, the more rollbacks they incurred — the opposite of what a maturing market should show. The issue is not that agents are useless. The issue is that rollback, monitoring, escalation, and evaluation become part of the cost of ownership. And the company eating that cost on an outcome-priced contract is not in the commodity middle. It is in the squeezed middle.
The resulting stack looks less like “models versus apps” and more like a three-layer margin transfer.
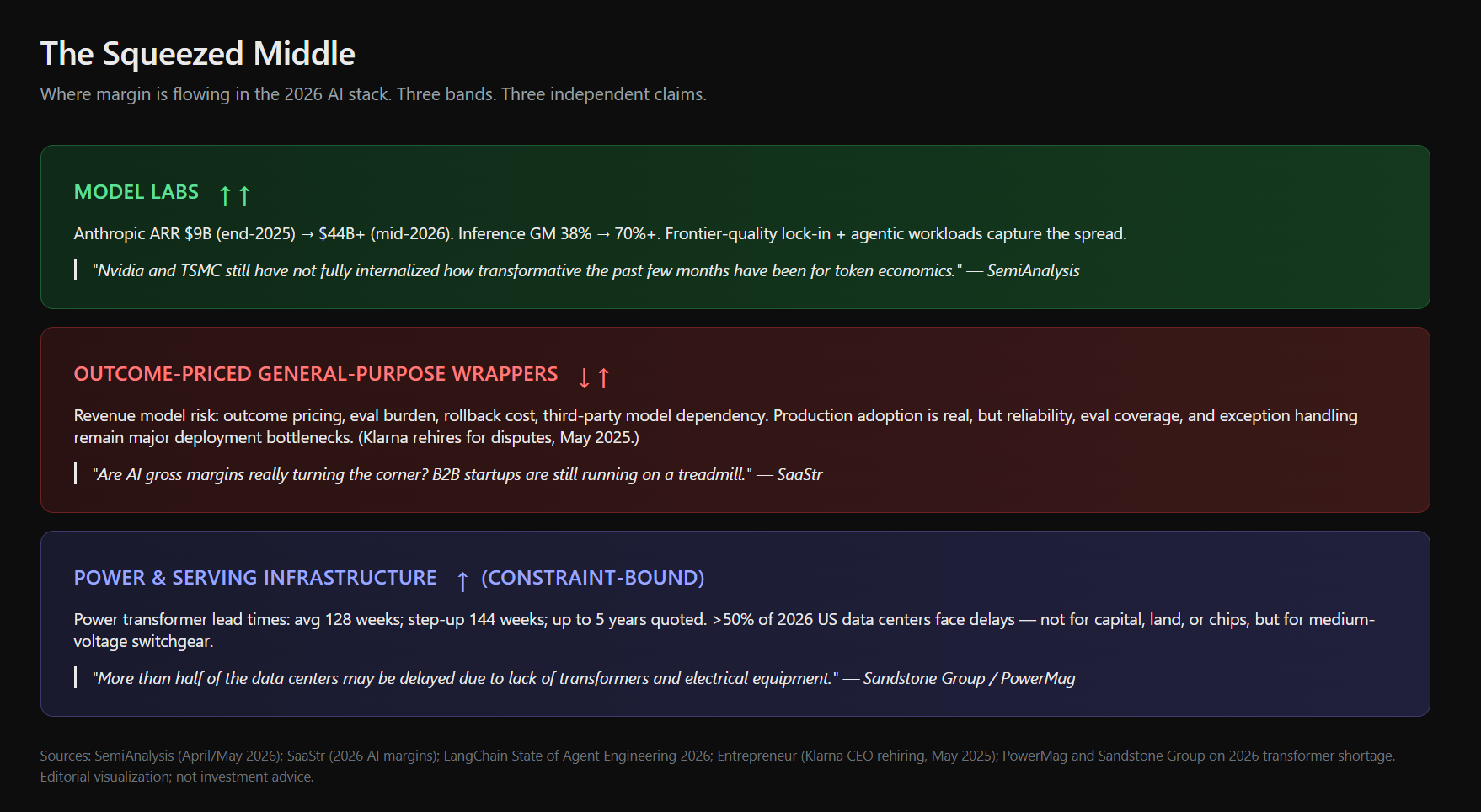
Where margin is flowing in the 2026 AI stack. Three independent claims: model-layer operating leverage, squeezed general-purpose wrappers, and constraint-bound power and serving infrastructure.
The Mechanism: A Refining Story, With a Semiconductor Caveat
The analogy worth holding here is not from software. It is from oil refining, 2005 to 2008.
For a decade before that window, refining was the dumb middle of the energy stack. Upstream had the resource. Downstream had the brand. Refiners took the toll. Margins ran in single digits per barrel for years.
Then the crack spread inverted. Crude prices spiked, but refined-product prices spiked faster, because you cannot permit and build a refinery on demand’s timeline. Valero’s margin per barrel went from single digits to over twenty dollars. The “commodity middle” became, for a window, the most profitable layer in the stack. Not because Valero suddenly developed brand power. Because the constraint structure shifted underneath everyone’s model, and the players who already owned refining capacity were the only ones who could meet demand.
That is what is happening at the model layer in 2026. But the analogy has a limit.
Refining implies a temporary spread. Refineries eventually get built. Capacity eventually catches up. Margins eventually normalize. That may still be true for parts of AI infrastructure, especially physical capacity. But frontier intelligence is not only physical capacity. It is also training data, model architecture, alignment iteration, evaluation systems, developer trust, inference reliability, and years of compounding engineering decisions.
In that sense, the model layer sometimes behaves less like refining and more like a semiconductor process node. When one company has a meaningful lead at the frontier, every application above it becomes partially dependent on what that layer can do. The constraint is not merely “who has capacity.” It is “who defines the capability frontier.”
That distinction matters. If this were only a refining story, the spread would be easier to underwrite as temporary. If it is partly a process-node story, the spread may last longer than commodity logic suggests.
Three forces are compounding.
First, the workload changed. Claude Code and its peers created an agentic coding workload where willingness to pay is set by displaced labor, not by the price of inference. A senior engineer costs hundreds of dollars an hour and sleeps. Two-and-a-half billion in ARR in nine months is the data point: that workload exists at scale.
Second, the inference stack got radically better. Dynamo and NIXL from NVIDIA. FlashInfer. LMCache. KV-cache compression. Serving cost-per-token fell faster than retail token prices fell. SemiAnalysis put it plainly: “Nvidia and TSMC still have not fully internalized how transformative the past few months have been for token economics.” The spread between cost-to-serve and price-to-charge widened.
But this was not a generic commodity improvement. The cost curve moved because inference became a full-stack systems problem. At production scale, latency and throughput are not determined only by raw GPU FLOPS. They depend on how prefill and decode are routed, how KV cache is managed across nodes, how memory bandwidth is used, how kernels are optimized, how network fabric is designed, and how serving frameworks schedule millions of requests under real-time constraints.
The margin did not appear simply because chips got faster or tokens got cheaper. It appeared because hardware, memory, networking, kernels, and serving software were optimized together. That is a systems engineering moat. It is harder to copy than a price cut.
Third, frontier quality became sticky. Agentic workloads cannot always route to the cheapest model. The cheapest model may fail the task, and the outcome-priced contract above may blow up. Frontier-quality lock-in captures the spread.
These three forces are independent. A reader can accept one and reject another. You can believe inference innovation is durable but doubt frontier lock-in. You can believe the quality gap is widening but worry the workload is Anthropic-specific. The thesis does not require you to swallow all three.
It requires only one conclusion: the model layer was not the dumb pipe in this window. It was closer to the constraint.
The Counter-Data That Complicates the Story
The cleanest counter-data point comes from The Information, which reports that even as Anthropic’s revenue skyrocketed, the company lowered its own internal profit margin projection. Revenue up. Internal margin guidance down.
This complicates the “model layer wins” narrative in a useful way. The spread is real. Anthropic is choosing to plow it into the next training run, compute build-out, and frontier widening — not bank it as profit. Which, if you run a model lab, is exactly the right move when the moat is the quality gap. But it means the public profit picture lags the spread by years. The bull case and the steelman bear case both have to live with that.
SemiAnalysis projects Anthropic profitability in 2028. It is a projection, not a guarantee. Worth saying out loud.
There is another complication: not every model lab becomes Anthropic. The model layer can capture operating leverage and still be brutally competitive. The right conclusion is not “models win.” The right conclusion is narrower: under the right workload, quality gap, and serving-cost curve, the model layer can behave like the leverage layer rather than the commodity layer.
That is enough to break the 2024 consensus.
The 1M-Token Gap
The frontier-quality argument got tested at the architectural level in late April 2026 when DeepSeek shipped V4. The headline was beautiful: one million tokens of context at roughly ten percent of the V3.2 KV cache. Day-zero patches landed from vLLM, SGLang, FlashInfer, TileKernels.
Then Digital Applied’s long-context needle-in-haystack evaluation — NIAH-2, 8-needle, April 2026 — showed the architectural cost. V4-Pro dropped thirty-seven points on multi-needle retrieval accuracy at one million tokens compared to the two-hundred-thousand-token baseline. GPT-5.5 dropped twenty-two points. Opus 4.7 dropped thirty-three.
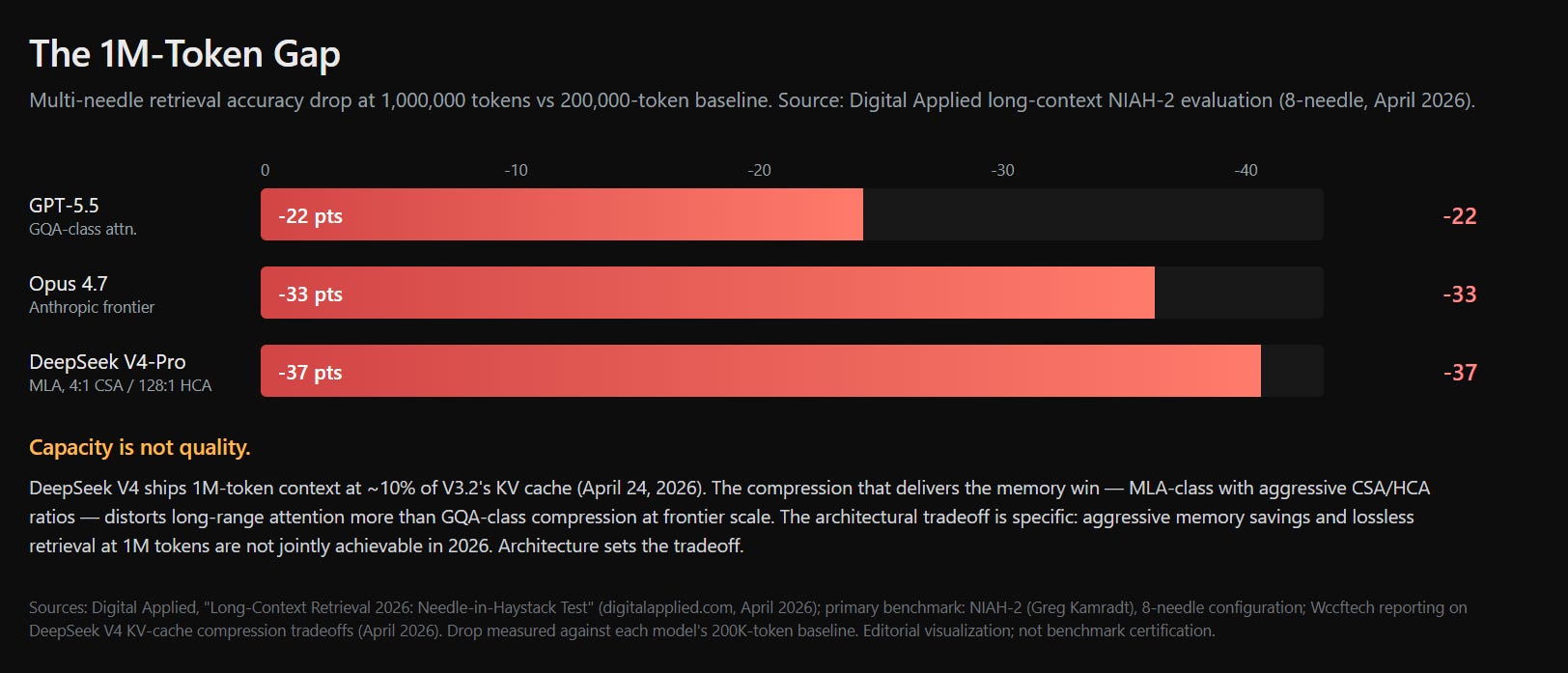
Multi-needle retrieval accuracy drop at 1M tokens vs. 200K baseline. Source: Digital Applied NIAH-2 evaluation. Editorial visualization; not benchmark certification.
DeepSeek did not fail. The architectural tradeoff is specific: MLA-class compression — four-to-one CSA, one-twenty-eight-to-one HCA — distorts long-range attention more than GQA-class compression does. In this window, aggressive memory savings and lossless retrieval at frontier scale appeared difficult to achieve together.
Capacity is not quality.
But the more precise conclusion is not that long-context quality is permanently scarce. The more precise conclusion is that long-context quality is sticky under current memory constraints.
KV cache at one million tokens is brutally expensive. A model provider has two choices: compress the cache aggressively and accept potential accuracy loss, or use more memory bandwidth and more HBM. That means the long-context quality gap is not only a model architecture question. It is also a memory hierarchy question.
As HBM bandwidth scales and serving architectures improve, the tradeoff curve can move. An architecture that looks like a quality sacrifice today may look like a rational interim decision tomorrow. The hardware ceiling is moving.
For the outcome-priced wrapper, however, that nuance does not help today. If it marketed a “million-token context window” to its customer and retrieval accuracy fails silently on the long tail, the contract pays nothing. The vendor eats the loss. Architecture sets the tradeoff. Memory bandwidth sets the boundary. The application absorbs the failure.
That is the squeeze.
The Pricing Reversal
By April 2026, Foundation Capital and Monetizely had each published material noting that agentic AI vendors were quietly walking back outcome pricing. Bessemer’s AI pricing playbook from the same period acknowledged the trend: flat monthly licenses were coming back. Seat-based subscription returned.
The mechanism is almost elegant. When inference cost-per-token collapsed roughly tenfold in eighteen months, the variance in a heavy user’s usage stopped mattering to the vendor. Flat pricing got more profitable, not less, because the tail cost was small. The 2024 outcome-pricing thesis was a 2024-cost-structure thesis. The cost structure moved.
The application middle is being squeezed from two directions at once. Above, model labs are capturing the spread. Below, cheap inference makes flat-license pricing safe for any vendor.
But that does not make the application layer unattractive. It changes the benchmark.
Many AI applications can still become very good businesses when compared against traditional SaaS or service-heavy incumbents. If an AI-native product automates labor, reduces implementation friction, improves user experience, or turns a manual workflow into software, it can create real value even if the model layer captures part of the margin.
The risk is not being an application.
The risk is being a thin, general-purpose application with no proprietary data, no workflow lock-in, no distribution advantage, and no control over failure modes.
That distinction matters for venture underwriting. The 2024 question was: “Can this app use AI?” The 2026 question is sharper: “What does this app own when the model gets better, cheaper, and more vertically integrated?”
If the answer is only UI, the business is exposed. If the answer is workflow, data, distribution, regulated trust, deployment depth, or failure-handling loops, the business may still be durable.
The Honest Caveats
Three places this thesis could be wrong.
One: Claude Code may be Anthropic-specific. The two-and-a-half-billion-in-nine-months number is not a model-layer-wide datum. If no other lab builds an equivalent high-WTP agentic workload, the spread compresses back to chat.
Two: SemiAnalysis projects Anthropic profitability in 2028. Projections are not guarantees, and The Information’s reporting on the lowered margin projection is a real signal. The model layer winning the spread and the model layer being profitable are not the same statement.
Three: the application middle being squeezed is not the same as applications losing. Vertical AI with proprietary data, regulated distribution, workflow ownership, or strong failure-handling loops is on a different curve.
The thesis does not need any of these caveats to fail in order to be useful. It needs you to underwrite from the top of the stack with eyes open about which sub-claim you are betting on.
The clearest disconfirmation would be if high-willingness-to-pay agentic workloads become reliably routable to cheaper models without degrading outcomes, while application vendors retain pricing power despite lower model differentiation.
That would mean the quality gap closed, the routing layer got good enough, and the application layer kept the customer relationship.
That is possible. It is just not what this window showed.
Where the Power Has to Go
The thesis does not end at the model layer. The frontier-quality spread that minted Anthropic’s margin is enforced, in the end, by copper and steel.
Average power transformer lead times in North America: over two years for standard units, closer to three for step-up transformers. One US maker is quoting five-year waits. Some industry estimates suggest more than half of the US data centers planned for 2026 could be delayed — not for capital, not for land, not for chips, but for medium-voltage switchgear.
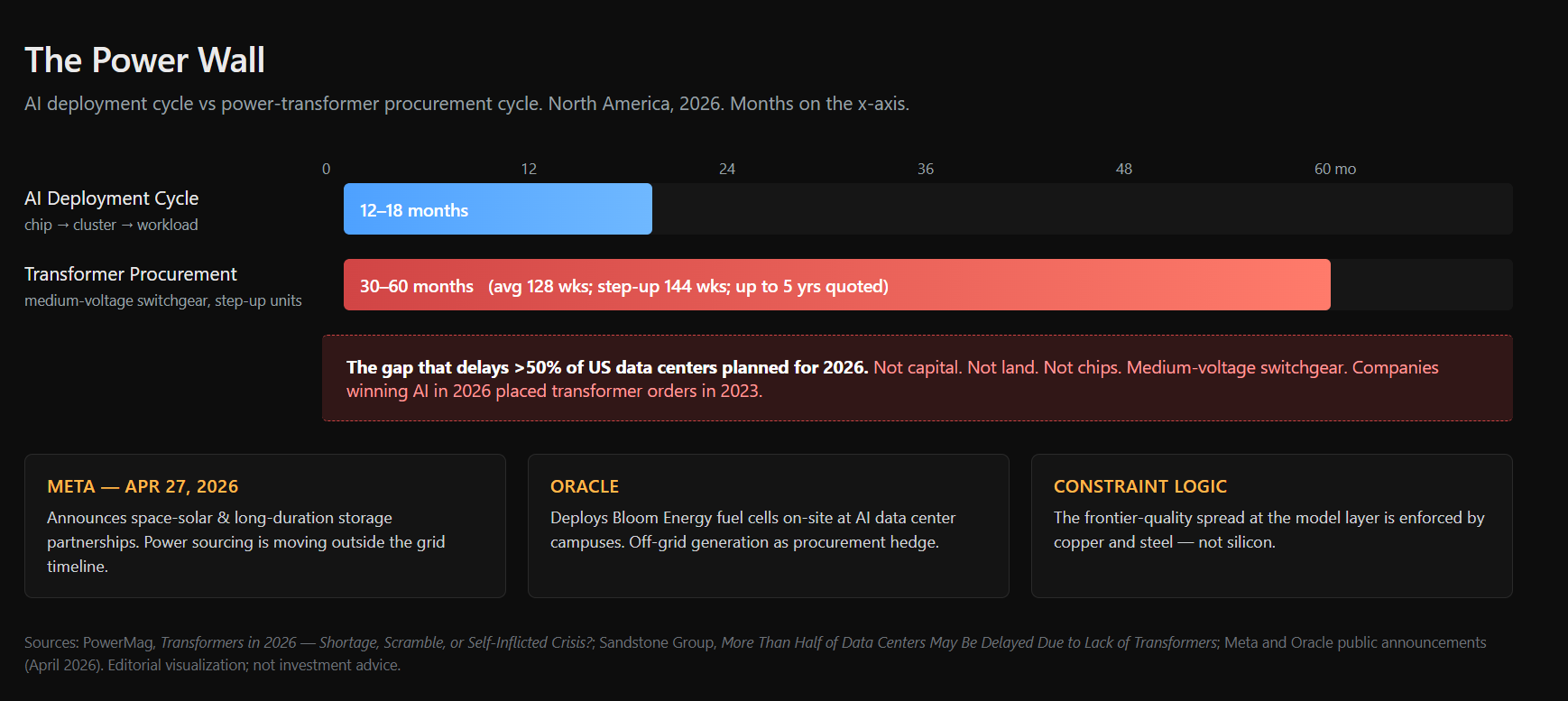
AI deployment cycle vs. transformer procurement cycle, North America 2026. Sources: PowerMag, Sandstone Group. The constraint is enforced by copper and steel, not silicon.
The AI deployment cycle is twelve to eighteen months. The transformer procurement cycle is thirty to sixty months. The companies winning AI in 2026 placed their transformer orders in 2023. Meta announced space-solar and long-duration storage partnerships on April 27. Oracle is deploying Bloom Energy fuel cells on-site.
The important point is not only that transformers are delayed. It is that energy procurement is becoming part of AI infrastructure strategy.
Grid interconnection, transmission capacity, on-site generation, storage, and power electronics are moving from back-office procurement into strategic advantage. The AI factory is not just a GPU cluster. It is a power system with models attached.
This is the same pattern again: the winner is the layer closest to the constraint.
When networking was the bottleneck, NVIDIA bought Mellanox. When inference serving became the bottleneck, the stack moved toward deeper co-design across hardware, kernels, cache, scheduling, and software. When power becomes the bottleneck, hyperscalers and AI labs will not wait politely for the grid. They will vertically integrate into generation, storage, and procurement.
The next infrastructure moat may be measured not only in FLOPS, but in secured megawatts.
The constraint structure that gives the model layer its operating leverage is downstream of the grid.
Re-underwriting the Stack
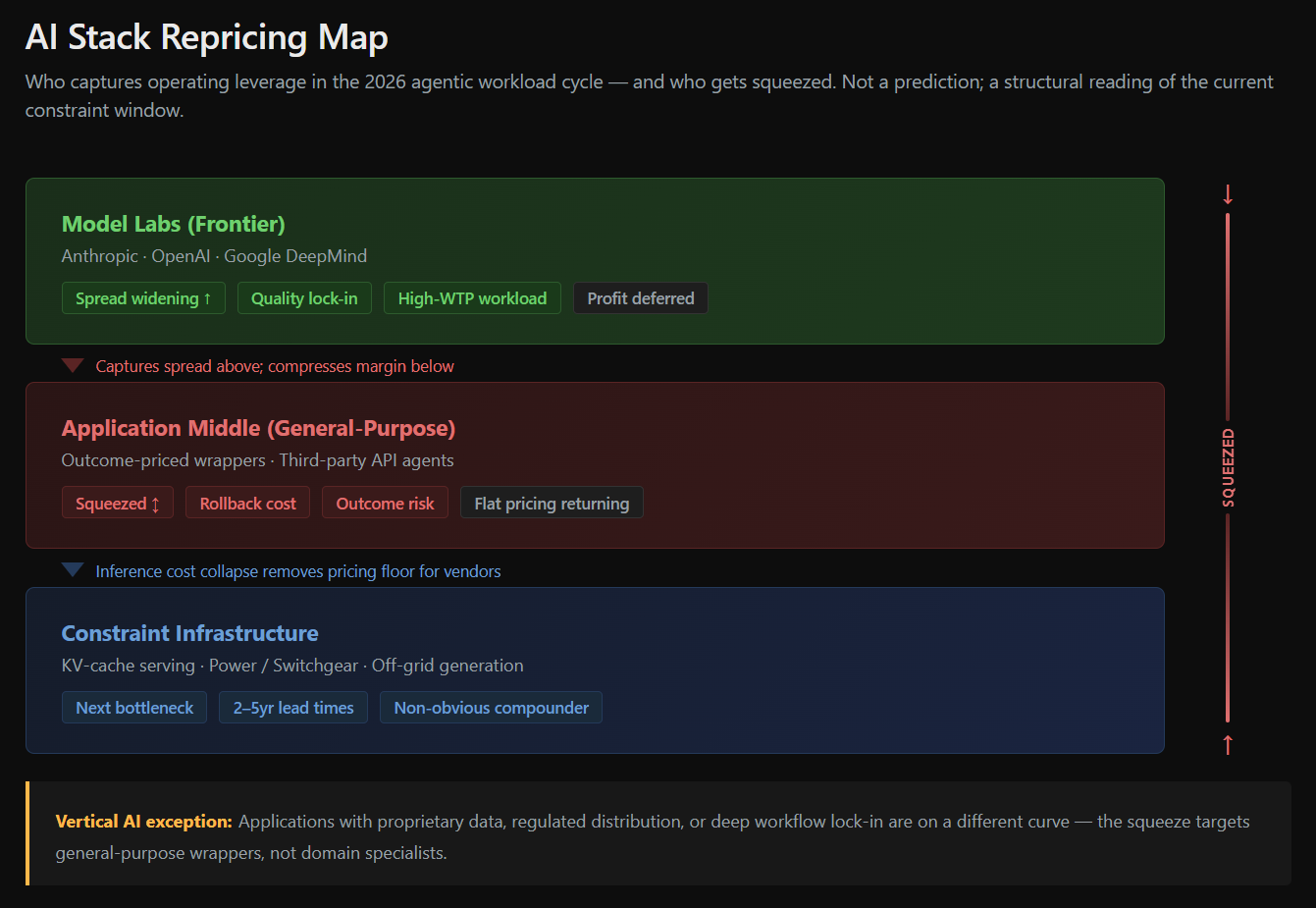
AI stack repricing map: model labs capture spread when quality gaps and high-WTP workloads align; general-purpose wrappers absorb outcome risk; physical and serving infrastructure captures value when constraints bind.
So the practical thesis, broken into three claims a reader can accept or reject independently:
Inference-stack innovation is real and durable. Cost-to-serve has fallen faster than price-to-charge. The spread has widened. But the important point is not just lower cost. It is systems-level co-design across silicon, memory, networking, kernels, cache, and serving software.
Frontier-quality spread is widening in the current window. Agentic workloads cannot always route to the cheapest model; capacity is not quality. But part of that quality gap is tied to memory constraints, and memory constraints can move.
The application middle is bifurcating. Thin, general-purpose, outcome-priced wrappers are being squeezed; vertical AI applications that compete against traditional SaaS or services can still create durable value when they own workflow, data, distribution, trust, or failure handling.
In this window, for high-willingness-to-pay agentic workloads, the model layer behaved less like a commodity middle and more like an operating-leverage layer. The riskiest place may be the thin, general-purpose, outcome-priced application middle — not every application business.
And the bottom of the stack — power, switchgear, off-grid generation, HBM, networking, KV-cache serving infrastructure — is where the next non-obvious compounder lives.
For founders, the lesson is that token cost is not only an API bill. It is architecture, pricing, evaluation, and failure-mode control.
For investors, the lesson is that “AI value accrues to applications” was too broad. Sometimes value accrues to the layer with the customer. Sometimes it accrues to the layer with the data. Sometimes it accrues to the layer with distribution.
But in constraint markets, value often accrues to the layer that controls the bottleneck.
The 2024 consensus treated the model layer like a road that would widen until the toll-taker went broke. The better analogy, for this window, was refining — with a semiconductor caveat. When demand changes faster than capacity can follow, the supposed commodity middle becomes the operating-leverage layer. And when the capability frontier itself becomes hard to replicate, the spread can last longer than commodity logic expects.
That does not mean the spread lasts forever. Refineries eventually get built. Capacity eventually catches up. Hardware ceilings move. Routing improves. Margins normalize.
The investor question is not whether this inversion is permanent.
It is how long the constraint lasts, who controls it, and where the next bottleneck moves when this one relaxes.
The winner is not always the layer with the most visible demand.
It is often the layer closest to the constraint.
Note on figures
Several company-level numbers in this piece are based on reported estimates, secondary summaries, or editorial visualizations rather than audited financial statements. I use them directionally to analyze stack economics, not as certified financials.
Sources
SemiAnalysis: AI Value Capture — The Shift to Model
OfficeChai summary of SemiAnalysis on Anthropic ARR
The Information: Anthropic Lowers Profit Margin Projection as Revenue Skyrockets
SaaStr: Have AI Gross Margins Really Turned the Corner?
Entrepreneur: Klarna CEO Reverses Course by Hiring More Humans, Not AI
LangChain: State of Agent Engineering 2026
Wccftech: DeepSeek V4 Cuts KV Cache by 90% at 1M Tokens — Aggressive Compression Risks
Digital Applied: Long-Context Retrieval 2026: Needle-in-Haystack Test
PowerMag: Transformers in 2026 — Shortage, Scramble, or Self-Inflicted Crisis
Sandstone Group: More Than Half of Data Centers May Be Delayed Due to Transformer Shortage
Bessemer Venture Partners: The AI Pricing and Monetization Playbook
Monetizely: The 2026 Guide to SaaS, AI, and Agentic Pricing Models